
Génération augmentée par récupération (mode RAG)
Traditionnellement, les modèles de langage à grande échelle (LLM) génèrent du contenu en ne s’appuyant que sur les informations apprises durant leur phase d’entraînement. Dans le domaine de l’IA générative, le mode RAG (Retrieval-Augmented Generation) peut éviter cela.
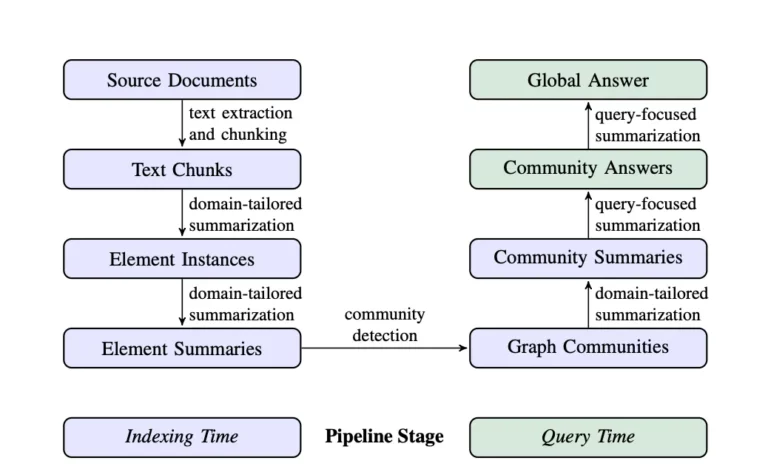
Le mode RAG passe par deux étapes :
- étape de récupération : quand le modèle reçoit une requête, il fait une rapide recherche dans un ensemble prédéfini de documents ou de données pour trouver et incorporer les informations les plus pertinentes par rapport à la requête. Cette phase initiale, aussi dite d'incorporations denses, nécessite que le modèle ait accès à une source qui peut être (selon les cas) une base de données vectorielle, un index de résumés, un index d’arbres, ou un index de table de mots-clés, etc.).
Un récupérateur de documents sélectionne les documents les plus pertinents au vu du prompt. Techniquement, cette pertinence est généralement déterminée en encodant sous forme de vecteur la requête ainsi que les documents, puis en identifiant les documents dont les vecteurs sont les plus proches en distance euclidienne du vecteur de requête ; - étape de génération : le LLM génère alors une sortie qui incorpore à la fois des informations provenant de la requête, des documents pertinents ainsi récupérés, et de ses connaissances internes.
Cette méthode est particulièrement bénéfique pour gérer des informations propriétaires ou dynamiques qui n’étaient pas incluses dans les phases initiales de formation ou de réglage fin du modèle.
RAG est également notable pour son utilisation de l'apprentissage few-shot, où le modèle utilise un petit nombre d’exemples, souvent récupérés automatiquement à partir d’une base de données, pour informer ses sorties. Le modèle peut alors utiliser les informations pertinentes ainsi récupérées, en plus de ses connaissance interne, pour générer une réponse ou un contenu (image, code..) conforme à la requête initiale, mais créé de manière plus informée et précise.
Le RAG invite le modèle d'IA à « consulter » — en temps réel — une base de données ou un corpus de documents externes. Si les données y sont bien indexées, ou si l'IA dispose d'outils perfectionnés de récupération d’informations, ces dernières seront susceptibles d'enrichir la génération de texte ou d'image par l'IA. Ceci améliore significativement la précision, la pertinence et la richesse du contenu généré25.
Le mode RAG s'avère par exemple utile pour générer des FAQ dynamiques, permettre à un chatbot d'administration ou d'entreprise de mieux répondre, respectivement, aux requêtes des citoyens et des clients (réponses plus personnalisées et précises). Il peut « créer des articles, des billets de blog, des descriptions de produits personnalisés pour le public cible ».
https://medium.com/@zilliz_learn/graphrag-explained-enhancing-rag-with-knowledge-graphs-3312065f99e1
https://www.oreilly.com/radar/unbundling-the-graph-in-graphrag